自動化鏈條中那個「看不見的」環節
當人們討論反指紋(anti-detect)瀏覽器裡一個 profile 的壽命時,通常會把重點放在瀏覽器指紋、代理(proxy)以及行為模式上。
但在這條鏈條裡,有一個經常被忽略的關鍵環節——你選擇了哪一個 CAPTCHA 解題服務。
而正是這個選擇,可能會把 profile 的存活時間(TTL)從數週壓縮到幾天,或者相反,延長到幾個月。
為什麼會這樣?因為錯誤地解 CAPTCHA,會在反機器人系統面前形成非常清晰的行為模式。當網站看到:
- 驗證碼在 1–3 秒內就被解出來(而正常人類需要 10–40 秒);
- 每五次嘗試就錯一次(而人類很少會超過 5% 的錯誤率);
- 答案在任何時段都以幾乎固定的速度送達;
- 在一次失敗之後,這個 profile 突然掉入無限的挑戰迴圈,永遠在刷驗證,
……它就會得出結論:這不是真實的人類,而是掛著自動 CAPTCHA 解題服務的機器人。
Profile 的偵測率(Detection Rate)開始飆升,TTL 下降。
原本一週才看到一次的 CAPTCHA,現在變成幾乎每做兩個動作就被丟一次驗證。
接下來,我們來拆解不同的 CAPTCHA 解題服務(2Captcha、SolveCaptcha、CapSolver、AntiCaptcha、CapMonster 等)如何影響自動化的關鍵指標:Detection Rate、TTL,以及每 1000 個動作所遭遇的 CAPTCHA 次數。
也順便說說,為什麼同一個 MuLogin profile,會出現「有時很活、 有時早就死透」這種情況——根本不是因為瀏覽器指紋變了,而只是因為你切換成了一個速度更「不正常」的解題服務。
反機器人系統如何偵測 CAPTCHA 解題服務
DataDome / Castle / Cloudflare 眼中的行為標記
現代防禦系統(DataDome、Castle、Radware Bot Manager 等)並不只是在看「CAPTCHA 有沒有被解出來」。
它們會分析這次解題周圍的數百個信號。
其中幾個關鍵指標是:
解題時間(Solve time)
典型的人類解題速度:
- 簡單文字型驗證碼:10–30 秒;
- 多輪 reCAPTCHA v2:20–60 秒,如果比較麻煩,有時會拖到 2–3 分鐘;
- 複雜的視覺拼圖或圖片點選題:30–120 秒。
CAPTCHA 解題服務(2Captcha、AntiCaptcha 等):
- 簡單驗證碼:5–15 秒;
- reCAPTCHA v2:10–20 秒。
混合式與純 AI 的 CAPTCHA 解題服務(SolveCaptcha、NoCaptchaAI):
- 簡單文字:3–5 秒;
- reCAPTCHA v2:1–3 秒(!)。
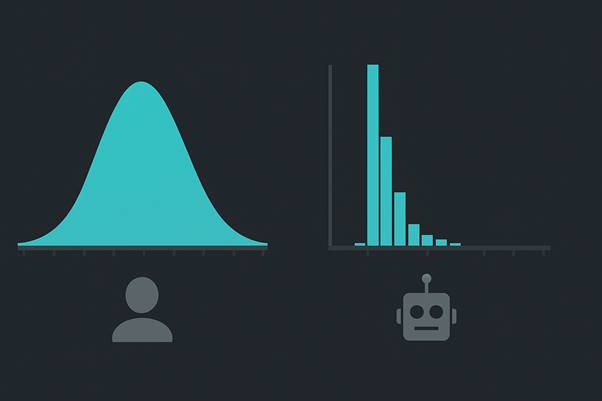
反機器人系統會針對每個 profile / IP 看一個解題時間分佈的直方圖。
如果這個分佈緊密地集中在 2–5 秒附近(尤其是對於困難題型),那就是一個非常明顯的風險信號。
錯誤與重試模式(Errors & retry patterns)
典型的人類行為:
- 大約 ~95% 的情況下第一次就答對;
- 如果答錯,會再試一到兩次(通常第二或第三次就成功);
- 錯誤在時間上是隨機分佈的,沒有固定模式。
手動型 CAPTCHA 解題服務:
- 只要有重試機制,整體正確率在 95–99% 左右;
- 但會偶爾出現很明顯的失誤(語言錯誤、字母顛倒等);
- 如果整合得不好:對於新服務,第一次嘗試可能有 1–5% 錯誤率。
混合式與純 AI 的 CAPTCHA 解題服務:
- 在簡單型驗證碼上的正確率:99% 以上;
- 在複雜或新型驗證碼上:可能只有 85–95%;
- 但在新題型上,錯誤的「規律性」本身就是一個信號(AI 往往會在同一類型上,一口氣以同樣方式失敗一批)。
週期性與「整齊劃一」的解答
反機器人系統也會檢查:對於同一種挑戰(同一類型),回傳答案的時間與結構是否太過一致(例如全部都在 3.2 秒內完成、答案格式完全同質)。
這樣的規律性,很容易被視為自動化行為。
真實使用者則混亂得多:有人 8 秒解完,有人 45 秒,有人會改用音訊 CAPTCHA,有人乾脆重整頁面再來。
從 TTL 與 Detection Rate 的角度比較不同 CAPTCHA 服務
現在我們來看看市場上的幾個主力玩家,如何影響 profile 的「健康狀態」。
服務核心指標
| Service | 類型 | 準確率 | reCAPTCHA v2 速度 | 簡單 CAPTCHA 速度 | 最大吞吐量 | 首次嘗試錯誤率 |
| 2Captcha | 手動 | 最高約 99% | 10–20 秒(平均約 20 秒) | 7–15 秒 | 高(約 10K/分) | 1–5%(取決於排隊情況) |
| SolveCaptcha | 混合式 | 最高約 99% | 4–13 秒(平均約 4.5 秒) | 2–5 秒 | 極高(約 12K/分) | 熱門類型 <1% |
| CapSolver | AI | 95–99%(在 reCAPTCHA v2/v3 上約 99%) | <1–3 秒 | <1 秒 | 非常高(>1000/分) | 新題型約 10–15% |
| CapMonster | AI | 95–99%(Google 類型約 99%) | <1–2 秒 | <1 秒 | 約 1000/分 | 標準題型 <5% |
| AntiCaptcha | 手動 | 95–99% | 10–20 秒 | 5–15 秒 | 高 | 1–5% |
| DBC (DeathByCaptcha) | 混合式 | 90–99% | 15–35 秒 | 5–10 秒 | 中等 | 2–8% |
| NoCaptchaAI | AI | 95–99% | 3–5 秒 | 0.2–0.5 秒 | 約 500/分 | 10–20% |
速度與穩定性往往是對立面。
最快的服務(CapSolver、CapMonster、NoCaptchaAI)是 AI 型,僅靠速度就會產生非常明顯的偵測信號;
最「像人類」的(2Captcha、AntiCaptcha)則相對較慢。
CAPTCHA 服務指標如何影響 profile 的 TTL 與 Detection Rate
假設你有一個 MuLogin profile,用在一個網站上,這個網站每天登入時會要求一次 CAPTCHA。
除此之外,這個 profile 非常「乾淨」:指紋品質好、住宅代理、動作之間的停頓也很自然。
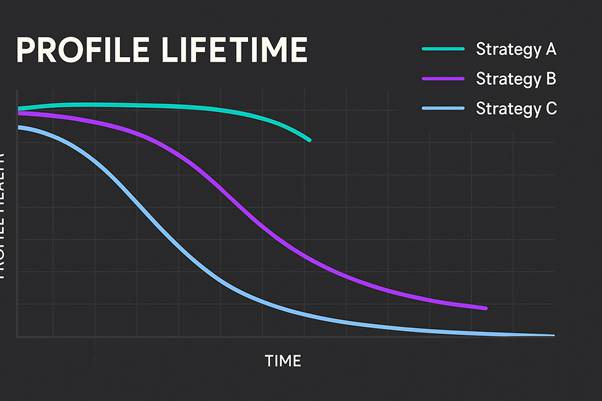
情境 A:你使用 DeathByCaptcha(混合式、偏快)
第一週:
- CAPTCHA 平均在約 4–5 秒內被解出;
- 網站開始注意到這個不自然的速度;
- Profile 的偵測率(Detection Rate)從 5%(基線)慢慢爬升到 ~15%。
第二週:
- 網站開始在輸入密碼與 2FA 時額外插入檢查;
- 你會開始收到「可疑活動」的 SMS 驗證要求;
- Profile 的 TTL 從原本預期的「2 個月」掉到約 2 週;
- Profile 尚未被封,但已經進入高風險評分區,幾乎持續被丟 CAPTCHA。
情境 B:你使用 2Captcha(純手動)
第一週:
- CAPTCHA 平均在 15–20 秒內解出;
- 這個速度恰好落在「人類範圍」(10–60 s)的中段;
- 網站沒有看到明顯的異常;
- 偵測率維持在基線:大約 5–8%。
第二週:
- 基本上什麼都沒變(或變化極慢);
- Profile 像正常帳號一樣又活了 2–3 週;
- 預期 TTL:3–4 個月(對於一個「非自然生成但被小心維護」的帳號來說,屬於正常範圍)。
情境 C:你使用 CapSolver(AI,極高速)
第一週:
- CAPTCHA 在 1–3 秒內解出(!);
- 這明顯超出人類的正常範圍(很少有使用者能反應這麼快);
- 網站立即拉高風險分數;
- 偵測率一口氣衝到 30–50%。
第二週:
- 幾乎每個動作都會被插 CAPTCHA 挑戰;
- Profile 進入「高度懷疑模式」,要求 2FA、SMS、Email 驗證;
- TTL 掉到只剩 3–5 天,之後你幾乎可以直接把這個 profile 判定為「報廢」。
解題品質與副作用
「粗糙錯誤」 vs 「完美解答」
這裡有一個悖論:過於完美的 CAPTCHA 解答,有時比犯錯更可疑。
為什麼?因為真實的人會:
- 偶爾輸入錯誤再修正(在難題上重試率可以高達 ~50%);
- 偶爾卡在迴圈裡(連試 3–5 次)最後乾脆重整頁面;
- 偶爾改用音訊驗證碼而不是圖片;
- 不會在 1 秒內解完一個 CAPTCHA。
2Captcha 與 AntiCaptcha —— 這些純手動服務 —— 偶爾會出現非常明顯的失誤:字母顛倒、模糊字猜錯等等。
但這反而有助於偽裝:
- 錯誤看起來就像「真實使用者第一次沒看清楚」;
- 後續重試也顯得非常自然;
- Profile 看起來就是一般會偶爾失誤的普通帳號。
CapSolver 與 CapMonster —— AI 型 CAPTCHA 解題服務 —— 幾乎不會出錯(99%+),而且幾乎瞬間解完。
這種「超人級完美」在反機器人系統眼裡,就是一個紅色警報。
實務建議:如果你正在使用 AI 型的 CAPTCHA 解題服務,請在程式中加入人工延遲(收到答案後再等 0.5–2 秒才送出),並且偶爾「刻意犯錯」(送一個錯誤答案,讓 CAPTCHA 重刷,再解一次)。
這樣整體行為會更接近人類。
SolveCaptcha 的特殊性:混合式模型
SolveCaptcha 在這個光譜上有一個很特別的位置。
它的運作方式:
- 簡單 CAPTCHA(文字、基礎圖片)→ 交給 AI(2–5 秒);
- 複雜 CAPTCHA(reCAPTCHA、新類型)→ 交給人工(10–20 秒)。
對 profile 的 TTL 來說,這意味著:
| CAPTCHA 類型 | 時間 | 對反機器人系統的模式 | 風險評級 |
| reCAPTCHA v2(簡單) | 4–5 秒 | AI,高速峰值 | 中等(雖然很快,但不至於荒謬) |
| reCAPTCHA v2(複雜) | 13–20 秒 | 手動,偏慢 | 低(看起來像真的在「掙扎」) |
| 簡單文字型 CAPTCHA | 2–3 秒 | AI,幾乎瞬間 | 高(太快) |
SolveCaptcha 更適合 2–3 輪的驗證挑戰(混合行為有優勢),
但對於簡單 CAPTCHA 反而很危險(3 秒內的 AI 解題,對反機器人系統是一個強烈信號)。
因此,如果你大部分工作流程都在使用 SolveCaptcha,
最好在程式裡加上延遲,讓簡單 CAPTCHA 的解題時間也被「拉長」。
由此可見:
- 就算你只是「有整合」 CAPTCHA 服務、實際上不常使用,它仍可能被偵測出來——例如透過瀏覽器擴充套件、API 呼叫紀錄或固定的提交延遲模式。
- 把 CAPTCHA 服務與其他可疑標記混用(過舊的 Chrome 核心、伺服器 IP、headless 瀏覽器)會形成一場「完美風暴」,非常容易被標記。
- 在不同日期切換服務(星期一用 2Captcha,星期二用 CapSolver)有時比一直用同一個服務還更可疑。
2Captcha vs SolveCaptcha 的詳細對比
架構與運作模式
2Captcha:
- 100% 手動解題;
- 數十萬名工人分佈在不同國家(主要是菲律賓、印度、委內瑞拉);
- 價格:每 1000 題約 $0.30–$5,依題型而定;
- 速度:5–30 秒,視伺服器負載而定;
- 重試:免費(第一次答案錯誤,可以重新送單,會有工人再解一次)。
SolveCaptcha:
- 混合式模型(AI + 手動);
- 簡單任務(OCR、基本圖片)走 AI,複雜任務交給人工;
- 價格:由於簡單 CAPTCHA 自動化,通常比 2Captcha 便宜約 20–30%;
- 速度:2–20 秒,依題型而異(簡單題更快);
- 重試:付費(若 AI 解錯,重送的任務會改給人工解,需要額外付費);
- API:完全相容 2Captcha(基本上改一行設定就能切換)。
關鍵指標對照表
| 指標 | 2Captcha | SolveCaptcha |
| Architecture(架構) | 100% 手動 | 混合式(AI + 手動) |
| Speed(simple CAPTCHA) | 10–15 秒 | 2–5 秒 |
| Speed(reCAPTCHA v2) | 15–30 秒 | 4–13 秒 |
| Speed(complex multi-round) | 30–60 秒 | 15–25 秒 |
| Average accuracy(平均準確率) | 95–99% | 95–99% |
| First-try errors(首次錯誤率) | 1–5% | <1%(熱門類型) |
| Price (relative)(價格・相對) | baseline(基準) | 低約 20–30% |
| Retry policy(重試策略) | free(免費) | paid(付費,主要針對複雜題型) |
| Type coverage(支援題型範圍) | 所有已知類型 | 所有已知類型 |
| Anti-bot speed signal(速度信號) | 中等(處於自然人類範圍) | 中高(對簡單題來說偏快,容易略顯可疑) |
使用場景
2Captcha 比較適合:
- 你想要最大程度的簡單、以及「純手動」這種清晰模型;
- 你要處理的是複雜情境(稀有 CAPTCHA 類型、非標準格式);
- 你對 AI 被偵測這件事有高度心理障礙(即使實際風險不一定那麼高);
- 你可以接受在複雜題型上多等 25–30 秒,而且不會把業務流程拖垮;
- 這個 profile 已經有較高的風險分數,你需要用「非常慢、非常保守」的方式幫它降溫。
SolveCaptcha 比較適合:
- 你需要在速度與成本之間取得平衡;
- 你的流量以簡單 CAPTCHA 為主(文字題、基本圖片);
- 你處理的是高流量場景,每節省幾百毫秒就等於省錢;
- 你有工程師可以在程式裡加延遲、加噪音,來掩飾 AI 的速度。
其他競品與它們對 profile TTL 的「危險等級」
除了 2Captcha 與 SolveCaptcha,市場上還有其他玩家。每一家對 profile 的風險曲線都不同。
CapSolver:極速帶來的高風險
特性:
- 100% AI;
- 速度:簡單題 <1 秒,reCAPTCHA v2 只要 1–3 秒;
- 準確率:在熱門題型上約 99%;
- 整合很多(Selenium、Puppeteer、瀏覽器擴充套件等);
- 價格:與其他 AI 服務相比,具競爭力。
對 profile TTL 的風險:極高(EXTREMELY HIGH)
原因很簡單:在 <1 秒內解完一題 CAPTCHA,幾乎不可能是人。
反機器人系統會立刻看到這個行為。
如果你直接「裸用」CapSolver(程式裡不加任何延遲):
- 第一週:偵測率 +30%;
- 第二週:再 +60%;
- 第三週:profile 不是進黑名單,就是被迫永遠走 2FA 流程。
如何相對安全地用 CapSolver:
- 每次取得答案後,強制等待 2–5 秒再提交;
- 定期注入「錯誤」(刻意送錯答案);
- 僅用於一次性、可拋棄的 profile(臨時 email、測試帳號等),不要用在長期維護的帳號上;
- 千萬不要拿 CapSolver 去解關鍵帳號(Email、Facebook、Amazon 等)的 CAPTCHA。
AntiCaptcha:保守且可靠
特性:
- 純手動(與 2Captcha 類似);
- 2007 年就已經在線;
- 99.99% 線上率(uptime);
- 速度:reCAPTCHA 約 10–20 秒。
對 profile TTL 的風險:低(LOW)
在速度與準確率上,AntiCaptcha 幾乎就是另一個 2Captcha,但:
- 在 bot 圈裡略微沒那麼普及;
- 線上率略高(如果你很怕服務中斷,這是加分點)。
什麼時候用:如果你已經有經驗、想要更多調教空間,可以選它;
如果沒有,就先從更簡單的 2Captcha 開始。
CapMonster:高速 AI,可靠性已被驗證
特性:
- 100% AI;
- 速度:<1 秒,和 CapSolver 一樣;
- 準確率:標準題型上約 99%;
- 每分鐘可處理 >1000 題;
- 不會對錯誤解答收費(與不少 AI 服務不同);
- 可模擬 2Captcha / AntiCaptcha 的 API,方便移植。
對 profile TTL 的風險:極高(與 CapSolver 同等)
故事一樣:<1 秒的解題時間,本身就是強烈信號。使用時要採取同樣的防範措施。
CapMonster 相對 CapSolver 的優勢在於:錯題不收費。
但這個優點並不能抵消被偵測的風險。
DBC(DeathByCaptcha):混合式的「黃金中間值」
特性:
- 混合式(OCR + 手動);
- 速度:簡單題約 9 秒,複雜題 15–35 秒;
- 準確率:90–99%(低於純手動服務);
- API 與 2Captcha / AntiCaptcha 相容;
- 算是相對老牌的服務(在現代 bot 場景中相對沒那麼流行)。
對 profile TTL 的風險:中等(MEDIUM)
DBC 是速度與「人味」之間的折衷方案。
不如純 AI 快,但也比純手動快。適合:
- 中等負載的場景;
- 對穩定性沒有極端要求的 profile;
- 你刻意想讓解題時間呈現「混合型分佈」的情境。
維持 profile TTL 的實用建議
根據任務類型選擇合適的 CAPTCHA 服務
| 任務 | 推薦服務 | 原因 |
| 長期存活的「真實」站點 profiles(FB、Instagram、Google) | 2Captcha 或 AntiCaptcha | 極度保守:CAPTCHA 出現頻率低,但一旦出現就以接近人類的自然速度解題,偵測風險最低。 |
| 中等負載爬取(價格爬蟲、監控) | SolveCaptcha | 在速度與自然行為之間取得平衡,成本較低,對不同 CAPTCHA 類型都有混合式(AI+手動)優勢。 |
| 大量註冊一次性 profiles(Email、測試帳號) | CapSolver 或 CapMonster | 速度才是重點,profile 的 TTL 並不關鍵,AI 服務可以提供極高吞吐量與極短解題時間。 |
| 高 QPS 批次處理 | SolveCaptcha 或 CapMonster | 吞吐量高、單位成本合理,適合需要大量並發解題的批次任務場景。 |
| 關鍵帳號(錢包、支付資訊) | 2Captcha(加上人工延遲) | 最保守的做法:純手動解題,在關鍵操作周圍盡量避免多餘自動化,並透過延遲模擬人類反應時間。 |
掩飾你正在使用的 CAPTCHA 服務:工程端的小技巧
即便你使用的是相對溫和的服務(SolveCaptcha、DBC),也可以透過一些手段降低被偵測的風險:
1. 加入隨機延遲
import time
import random
def solve_captcha_with_delay(service, captcha_id):
“””
解 CAPTCHA,並在送出答案前加入自然的延遲
“””
result = service.solve(captcha_id) # 例如 SolveCaptcha.submit()
# 基礎延遲依 CAPTCHA 類型而定
base_delay = random.uniform(8, 15) # 若 service_speed < 5 秒,就額外等 8-15 秒
jitter = random.uniform(0, 3) # 再加 0-3 秒的隨機抖動
time.sleep(base_delay + jitter)
return result
|
2. 偶爾「刻意犯錯」
import random
def maybe_fail_captcha(fail_rate=0.03):
“””
在 3% 的情況下,刻意送出錯誤答案,
讓行為看起來更像人類
“””
if random.random() < fail_rate:
return False # 模擬失敗
return True
|
3. 不同 CAPTCHA 類型用不同服務
def solve_captcha(captcha_type, captcha_data):
“””
不同題型使用不同服務,整體行為會更自然
“””
if captcha_type == “recaptcha_v2”:
# 複雜多輪驗證 → 用手動(較慢)
service = AntiCaptcha()
time.sleep(random.uniform(2, 5)) # 送出前再加一點延遲
elif captcha_type == “image_simple”:
# 簡單圖片 → 用混合式(但同樣加延遲)
service = SolveCaptcha()
time.sleep(random.uniform(5, 10)) # 掩飾 AI 的快速解題
else:
service = TwoCaptcha() # 回退到最保守的選項
return service.solve(captcha_data)
|
監控 profile 指標
要判斷你選擇的 CAPTCHA 服務是否正在影響 profile 的 TTL,必須記錄一些指標。
範例結構:
{
“profile_id”: “abc123”,
“date”: “2025-12-03”,
“captcha_service”: “SolveCaptcha”,
“metrics”: {
“captchas_served”: 3,
“captchas_solved”: 3,
“avg_solve_time_seconds”: 4.2,
“solve_errors”: 0,
“detection_events”: 2, // 「可疑」事件 / 額外挑戰
“smtp_confirmations_requested”: 1, // SMS / Email 驗證次數
“profile_ttl_remaining_days”: 18
}
} |
如果你發現:
– avg_solve_time_seconds < 3 → 這個 profile 已經很危險,應該換成 2Captcha 等較慢的服務;
– detection_events 每天都在成長 → 換服務;
– profile_ttl_remaining_days 以每天 −1 天的速度在掉(正常情況大概是每天 −0.2)→ 是你現在的 CAPTCHA 服務在「毒殺」這個 profile。
CAPTCHA 服務如何觸發無限挑戰迴圈
「Infinite Challenge Loop」 模式
在很多防禦系統中(Cloudflare、hCaptcha、針對 Brave / 隱私瀏覽器的 Google reCAPTCHA),
有一種被充分記錄的行為模式:
當網站觀察到:
- CAPTCHA 以 1–3 秒的速度被解開;
- 重試率很高(同一題被解了 3 次以上);
- 序列異常(所有 CAPTCHA 都集中在 1 分鐘內完成,接著長時間沒動作,又突然爆一波),
……它就可能啟用「高度懷疑模式」,在這個模式下:
- 幾乎每個動作都會被丟 CAPTCHA,而不是只在關鍵操作才驗證;
- 就算你解過一次,30 秒後又會跳出新的;
- 有時候一旦你改用音訊驗證碼,反而會被自動封鎖(因為假設 bot 聽不到音訊);
- 唯一的解法就是關掉瀏覽器,整個 profile 放著幾個小時不動。
這種狀態可能持續好幾天——直到網站背後的 ML 模型「冷靜下來」,把你重新分類為正常使用者為止。
如何避免:
- 不要切換到過快的 CAPTCHA 服務;
- 在 CAPTCHA 之間拉開間隔(如果業務流程允許);
- 不要把同一題 CAPTCHA 連續重送兩次(網站看得到);
- 若你已經掉入迴圈,請暫停操作 6–24 小時,讓 profile「冷卻」。
「被拆來拆去」的 profile 症候群
有一種很怪的現象:如果你把多個服務混著用(第一天 CapSolver、第二天 2Captcha、第三天 SolveCaptcha),
結果可能比老老實實一直用同一個、就算稍微慢一點的服務還差。
為什麼?因為反機器人系統會看到:
12:34 —- CAPTCHA 在 1.2 秒內解完(CapSolver —- AI)
14:22 —- CAPTCHA 在 18 秒內解完(2Captcha —- 手動)
16:45 —- CAPTCHA 在 4 秒內解完(SolveCaptcha —- 混合式) |
這看起來就像是「這個 profile 一下子掛在 bot 上,一下子掛在人類身上」,
明顯哪裡不對。系統很容易把這解讀成「刻意輪換服務來規避偵測」。
建議:一個 profile 用一個 CAPTCHA 服務就好,盡量固定。
如果要換,頻率要很低(最多一個月一次),而且要有合理的「故事」(例如:舊服務出了資安問題)。
快速選擇表
可以把下面這張表當成隨手參考:
| 情境 | 服務 | 典型 TTL | 偵測率 | 成本(相對基準) | 備註 |
| 長期 profile(>3 個月) | 2Captcha | 90–120 days | 8–12% | 1.0x | 最保守,偵測率緩慢上升 |
| 中期 profile(30–60 天) | SolveCaptcha + 延遲 | 45–60 days | 12–18% | 0.7x | 需要工程端加入延遲與行為偽裝 |
| 短期 profile(7–14 天) | CapSolver | 10–14 days | 25–35% | 0.6x | 速度快,但 profile 風險高,易被快速偵測 |
如何不要因為選錯 CAPTCHA 服務,直接「殺死」一個 profile

不要在長期 profile 上裸用 CapSolver / CapMonster(不加任何延遲)。
它們會在 2–3 週內把 profile 玩壞。
- 如果你不知道該選什麼,2Captcha 是保守的預設值。
它比較慢,但紅旗較少,profile 的 TTL 可能比 AI 服務高出 3–4 倍。 - SolveCaptcha 是折衷方案。
如果你有工程師可以加「時間噪音」與延遲,它在價格 / 效能上很理想;
如果完全不做 masking,就會變得風險偏高。 - 不同 CAPTCHA 類型搭配不同服務(複雜用手動、簡單用 AI)是可行策略,
但務必在目標網站上實測其效果。 - 持續追蹤指標:若 avg_solve_time 與 detection_events 同步線性上升,
通常就是你目前的 CAPTCHA 服務在慢性「毒害」 profile —— 該換了。 - 一個 profile 一個服務,不要頻繁切換。
在反機器人眼裡,那看起來像是在刻意規避偵測。 - 就算你用的是保守服務,也請在程式裡加上隨機延遲與偶發的「人為失誤」。
光是這一點,就能額外把 TTL 拉長 20–30%。
選擇 CAPTCHA 解題服務,絕對不是單純的「省不省錢」問題。
它是決定 profile 生存能力的關鍵因素之一,卻常常被忽略,相較之下大家反而更執著於瀏覽器指紋與代理。
但實際上,一個錯誤的選擇,就足以燒掉你整座 profile 牧場。